一文读懂分布式数据库TiDB存储引擎原理 |
您所在的位置:网站首页 › mysql官网文档 幻读 › 一文读懂分布式数据库TiDB存储引擎原理 |
一文读懂分布式数据库TiDB存储引擎原理
|
一、TiDB简介 TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据 库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求 较高、数据规模较大等各种应用场景。 和TiDB相似的数据库还有cockroachdb,cockroachdb内部支持协议是postgresql。TiDB支持MySQL的原因是国内使用MySQL的相对较多。 通常情况下,OLAP一般通过ELK将需要分析处理的数据从数据库中导出,然后再用工具进行分析;TiDB将线上事务和数据分析都融合到分布式中一起处理(使用SQL语句分析)。 TiDB是分布式关系型数据库,支持HTAP(融合型的分布式数据库,融合了OLTP和OLAP),支持水平扩展,兼容MySQL 5.7,不再是轻量简单的SQl的响应速度而是在于大量高并发SQl的吞吐。  TiDB简介二、分布式系统的概念 TiDB简介二、分布式系统的概念分布式系统是一种其组件位于不同的联网计算机上的系统,然后通过互相传递消息来进行通讯和协调,为了达到共同的目标,这些组件会相互作用。换句话说,分布式系统把需要进行大量计算的工程数据分割成若干个小块,由多台计算机分别进行计算和存储,然后将结果统一合并到数据结论的科学。本质 上就是进行数据存储与计算的分治。 CAP 理论: 一致性(C):指所有的节点在同一时间的数据一致性。可用性(A):服务在正常响应时间内的可用。分区容错性(P):分布式系统在遇到某节点或网络分区故障的时候仍然能够对外提供满足一致性或可用性的服务。三、应用场景(1)对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高 的金融行业属性的场景。 TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同 的机房、机架、机器,当部分机器出现故障时系统可自动进 行切换,确保系统的 RTO TiDB数据库整体架构6.1、TiDB Server 的模块 SQL 层,对外暴露 MySQL 协议的连接endpoint,负责接受客 户端的连接,执行 SQL 解析和优化,最终生成分布式执行计 划。 TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统 一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例 上以达到负载均衡的效果。 TiDB Server 本身并不存储数据,只是解析SQL,将实际的数据读取请求转发给底层的存储节点TiKV(或 TiFlash)。 6.1.1、数据映射关系数据与 KV 的映射关系中定义如下: tablePrefix = []byte{'t'} recordPrefixSep = []byte{'r'} indexPrefixSep = []byte{'i'}假设表结构如下: CREATE TABLE User ( ID int, Name varchar(20), Role varchar(20), Age int, UID int, PRIMARY KEY (ID), KEY idxAge (Age), UNIQUE KEY idxUID (UID) );假设表数据如下: 1, "TiDB", "SQL Layer", 10, 10001 2, "TiKV", "KV Engine", 20, 10002 3, "PD", "Manager", 30, 10003 6.1.2、表数据与 KV 的映射关系Key 的形式: tablePrefix{TableID}_recordPrefixSep{RowID} 。 Value 的形式:[col1, col2, col3, col4] 。 映射示例: t10_r1 --> ["TiDB", "SQL Layer", 10, 10001] t10_r2 --> ["TiKV", "KV Engine", 20, 10002] t10_r3 --> ["PD", "Manager", 30, 10003]6.1.3、索引数据和 KV 的映射关系(1)对于唯一索引: Key 的形式: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue。Value 的形式: RowID 。映射示例:t10_i1_10001 --> 1 t10_i2_10002 --> 2 t10_i3_10003 --> 3(2)非唯一索引: Key 的形式: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID} 。Value 的形式:null 。映射示例:# 假设 IndexID 为 1 t10_i1_10_1 --> null t10_i1_20_2 --> null t10_i1_30_3 --> null6.2、PD(Placement Driver)Server整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实 时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅 存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状 态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群 的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可 用的能力。建议部署奇数个 PD 节点。 6.2.1、调度需求(1)作为一个分布式高可用存储系统,必须满足的需求,包括几种: 副本数量不能多也不能少。副本需要根据拓扑结构分布在不同属性的机器上。节点宕机或异常能够自动合理快速地进行容灾。(2)作为一个良好的分布式系统,需要考虑的地方包括: 维持整个集群的 Leader 分布均匀。维持每个节点的储存容量均匀。维持访问热点分布均匀。控制负载均衡的速度,避免影响在线服务。管理节点状态,包括手动上线/下线节点。满足第一类需求后,整个系统将具备强大的容灾功能。满足第 二类需求后,可以使得系统整体的资源利用率更高且合理,具 备良好的扩展性。 6.2.2、调度操作 增加一个副本 。删除一个副本 。将 Leader 角色在一个 Raft Group 的不同副本之间 transfer (迁移)。 6.2.3、信息收集 每个 TiKV 节点会定期向 PD 汇报节点的状态信息。每个 Raft Group 的 Leader 会定期向 PD 汇报 Region 的状态信息。6.3、存储节点 存储节点6.3.1、TiKV Server 存储节点6.3.1、TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 KeyValue 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开 区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层 面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后, 会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数 据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本 (默认为三副本),天然支持高可用和自动故障转移。  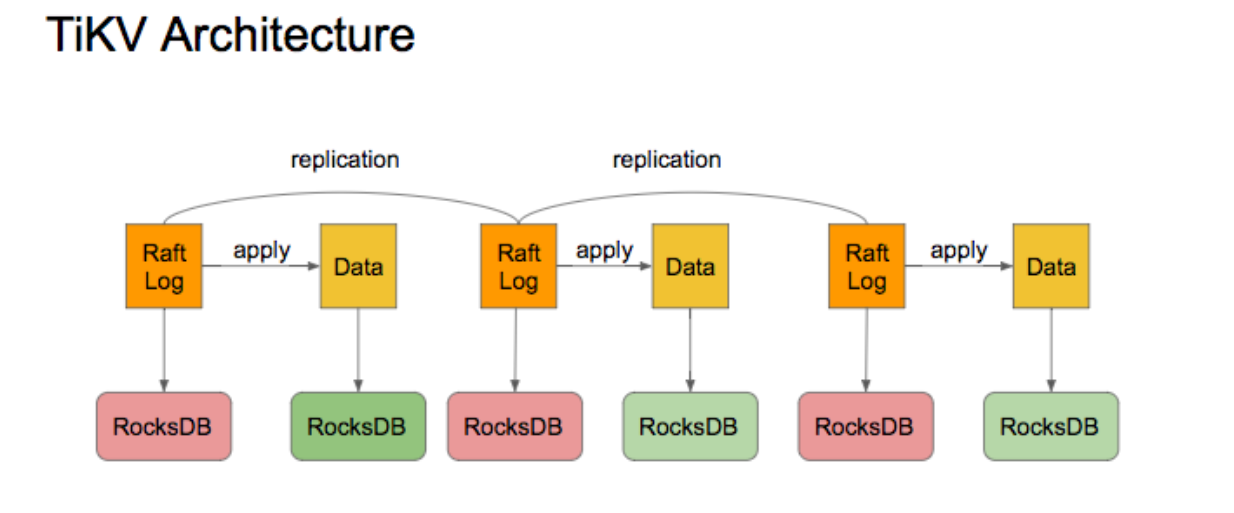 TiKV架构6.3.2、TiFlash TiKV架构6.3.2、TiFlashTiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的 是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功 能是为分析型的场景加速。  列式存储可以满足快速读取特定列的需求,在线分析处理往往需 要在上百列的宽表中读取指定列分析; 列式存储就近存储同一列的数据,使用压缩算法可以得到更高的 压缩率,减少存储占用的磁盘空间;6.4、RocksDB 列式存储可以满足快速读取特定列的需求,在线分析处理往往需 要在上百列的宽表中读取指定列分析; 列式存储就近存储同一列的数据,使用压缩算法可以得到更高的 压缩率,减少存储占用的磁盘空间;6.4、RocksDBRocksDB 作为 TiKV 的核心存储引擎,用于存储 Raft 日志以及用户数据。每个 TiKV 实例中有两个 RocksDB 实例,一个用于 存储 Raft 日志(通常被称为 raftdb),另一个用于存储用户数 据以及 MVCC 信息(通常被称为 kvdb)。kvdb 中有四个 ColumnFamily:raft、lock、default 和 write: raft 列:用于存储各个 Region 的元信息。仅占极少量空间,用 户可以不必关注。 lock 列:用于存储悲观事务的悲观锁以及分布式事务的一阶段 Prewrite 锁。当用户的事务提交之后,lock cf 中对应的数据会很快删除掉,因此大部分情况下 lock cf 中的数据也很少(少于 1GB)。如果 lock cf 中的数据大量增加,说明有大量事务等待提交,系统出现了 bug 或者故障。 write 列:用于存储用户真实的写入数据以及 MVCC 信息(该数 据所属事务的开始时间以及提交时间)。当用户写入了一行数据 时,如果该行数据长度小于 255 字节,那么会被存储 write 列 中,否则的话该行数据会被存入到 default 列中。由于 TiDB 的 非 unique 索引存储的 value 为空,unique 索引存储的 value 为主键索引,因此二级索引只会占用 writecf 的空间。 default 列:用于存储超过 255 字节长度的数据。6.4.1、内存占用为了提高读取性能以及减少对磁盘的读取,RocksDB 将存储在磁盘上的文件都按照一定大小切分成 block(默认是 64KB), 读取 block 时先去内存中的 BlockCache 中查看该块数据是否存在,存在的话则可以直接从内存中读取而不必访问磁盘。 BlockCache 按照 LRU 算法淘汰低频访问的数据,TiKV 默认将 系统总内存大小的 45% 用于 BlockCache,用户也可以自行修 改 storage.block-cache.capacity 配置设置为合适的值,但是不建议超过系统总内存的 60%。 写入 RocksDB 中的数据会写入 MemTable,当一个 MemTable 的大小超过 128MB 时,会切换到一个新的 MemTable 来提供写入。TiKV 中一共有 2 个 RocksDB 实例, 合计 4 个 ColumnFamily,每个 ColumnFamily 的单个 MemTable 大小限制是 128MB,最多允许 5 个 MemTable 存 在,否则会阻塞前台写入,因此这部分占用的内存最多为 4 x 5 x 128MB = 2.5GB。这部分占用内存较少,不建议用户自行更改。 6.4.2、空间占用多版本:RocksDB 作为一个 LSM-tree 结构的键值存储引擎, MemTable 中的数据会首先被刷到 L0。L0 层的 SST 之间的范围 可能存在重叠(因为文件顺序是按照生成的顺序排列),因此同 一个 key 在 L0 中可能存在多个版本。当文件从 L0 合并到 L1 的 时候,会按照一定大小(默认是 8MB)切割为多个文件,同一 层的文件的范围互不重叠,所以 L1 及其以后的层每一层的 key 都只有一个版本。空间放大:RocksDB 的每一层文件总大小都是上一层的 x 倍, 在 TiKV 中这个配置默认是 10,因此 90% 的数据存储在最后一层,这也意味着 RocksDB 的空间放大不超过 1.11(L0 层的数据较少,可以忽略不计)。TiKV 的空间放大:TiKV 在 RocksDB 之上还有一层自己的 MVCC,当用户写入一个 key 的时候,实际上写入到 RocksDB 的是 key + commit_ts,也就是说,用户的更新和删除都是会写入新的 key 到 RocksDB。TiKV 每隔一段时间会删除旧版本的数据(通过 RocksDB 的 Delete 接口),因此可以认为用户存储在 TiKV 上的数据的实际空间放大为,1.11 加最近 10 分钟内写入 的数据(假设 TiKV 回收旧版本数据足够及时)。6.4.3、compactRocksDB 中,将内存中的 MemTable 转化为磁盘上的 SST 文 件,以及合并各个层级的 SST 文件等操作都是在后台线程池中 执行的。后台线程池的默认大小是 8,当机器 CPU 数量小于等 于 8 时,则后台线程池默认大小为 CPU 数量减一。通常来说, 用户不需要更改这个配置。如果用户在一个机器上部署了多个 TiKV 实例,或者机器的读负载比较高而写负载比较低,那么可 以适当调低 rocksdb/max-background-jobs 至 3 或者 4。 6.4.4、WriteStall(写停顿)RocksDB 的 L0 与其他层不同,L0 的各个 SST 是按照生成顺序 排列,各个 SST 之间的 key 范围存在重叠,因此查询的时候必 须依次查询 L0 中的每一个 SST。为了不影响查询性能,当 L0 中的文件数量过多时,会触发 WriteStall 阻塞写入。 如果用户遇到了写延迟突然大幅度上涨,可以先查看 Grafana RocksDB KV 面板 WriteStall Reason 指标,如果是 L0 文件数 量过多引起的 WriteStall,可以调整下面几个配置到 64。 rocksdb.defaultcf.level0-slowdown-writes-trigger rocksdb.writecf.level0-slowdown-writes-trigger rocksdb.lockcf.level0-slowdown-writes-trigger rocksdb.defaultcf.level0-stop-writes-trigger rocksdb.writecf.level0-stop-writes-trigger rocksdb.lockcf.level0-stop-writes-trigger七、TiDB 部署本地测试集群# 下载并安装 TiUP curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh # 声明全局环境变量 source .bash_profile # 运行最新版本的 TiDB 集群, 其中 TiDB、TiKV、PD 和 TiFlash 实例各 1 个 tiup playground # 如果想指定版本并运行多个 tiup playground v4.0.16 --db 3 --pd 3 --kv 3 --monitor # 注意: 按照上面的部署, 在结束部署测试后 TiUP 会清理掉原集群数据,重新执行该命令后会得到一个全新的集群。 # 如果希望持久化数据, 并指定存储目录为 /tmp/tidb tiup playground -T /tmp/tidb启动异常的排除方式: MySQL启动异常时,需要通过日志来查看问题。TiDB会有一个工具dashboard,在网页输入IP:2379/dashboard就可以通过控制台查看日志,默认情况下密码为空。这个工具连接的是PD集群。 如果默认启动失败,可以知道host,使windows也可以访问数据库。比如:tiup playground -T /tmp/tidb --host 0.0.0.0八、数据测试(Bookshop) 如果默认启动失败,可以知道host,使windows也可以访问数据库。比如:tiup playground -T /tmp/tidb --host 0.0.0.0八、数据测试(Bookshop)Bookshop 是一个虚拟的在线书店应用,你可以在 Bookshop 当中便捷地购买到各种类别的书,也可以对你看过的书进行点 评。 tiup demo bookshop prepare参数简写默认值说明--host-H127.0.0.1数据库地址--port-P4000数据库端口--user-Uroot数据库用户--password-p无数据库用户密码--db-Dbookshop数据库名称参数默认值解释–users10000指定在 users 表生成的数据行数–authors20000指定在 authors 表生成的数据行数–books20000指定在 books 表生成的数据行数–orders300000指定在 orders 表生成的数据行数–ratings300000指定在 ratings 表生成的数据行数8.1、books 表该表用于存储书籍的基本信息。 字段名类型含义idbigint(20)书籍的唯一标识titlevarchar(100)书籍名称typeenum书籍类型(如:杂志、动漫、教辅等)stockbigint(20)库存pricedecimal(15,2)价格published_atdatetime出版时间8.2、authors 表该表用于存储作者的基本信息。 字段名类型含义idbigint(20)作者的唯一标识namevarchar(100)姓名gendertinyint(1)生理性别 (0: 女, 1: 男,NULL: 未知)birth_yearsmallint(6)生年death_yearsmallint(6)卒年8.3、users 表该表用于存储使用 Bookshop 应用程序的用户。 字段名类型含义idbigint(20)用户的唯一标识balancedecimal(15,2)余额nicknamevarchar(100)昵称8.4、ratings 表该表用于存储用户对书籍的评分记录。 字段名类型含义book_idbigint书籍的唯一标识(关联至 [books])user_idbigint用户的唯一标识(关联至 [users])scoretinyint用户评分 (1-5)rated_atdatetime评分时间8.5、book_authors 表一个作者可能会编写多本书,一本书可能需要多个作者同时编 写,该表用于存储书籍与作者之间的对应关系。 字段名类型含义book_idbigint(20)书籍的唯一标识(关联至 [books])author_idbigint(20)作者的唯一标识(关联至 [authors])8.6、orders 表该表用于存储用户购买书籍的订单信息。 字段名类型含义idbigint(20)订单的唯一标识book_idbigint(20)书籍的唯一标识(关联至 [books])user_idbigint(20)用户唯一标识(关联至 [users])quantitytinyint(4)购买数量ordered_atdatetime购买时间8.7、数据库初始化如果你希望手动创建 Bookshop 应用的数据库表结构,你可以运行 以下 SQL 语句: CREATE DATABASE IF NOT EXISTS `bookshop`; DROP TABLE IF EXISTS `bookshop`.`books`; CREATE TABLE `bookshop`.`books` ( `id` bigint(20) AUTO_RANDOM NOT NULL, `title` varchar(100) NOT NULL, `type` enum('Magazine', 'Novel', 'Life','Arts', 'Comics', 'Education & Reference','Humanities & Social Sciences', 'Science & Technology', 'Kids', 'Sports') NOT NULL, `published_at` datetime NOT NULL, `stock` int(11) DEFAULT '0', `price` decimal(15,2) DEFAULT '0.0', PRIMARY KEY (`id`) CLUSTERED ) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; DROP TABLE IF EXISTS `bookshop`.`authors`; CREATE TABLE `bookshop`.`authors` ( `id` bigint(20) AUTO_RANDOM NOT NULL, `name` varchar(100) NOT NULL, `gender` tinyint(1) DEFAULT NULL, `birth_year` smallint(6) DEFAULT NULL, `death_year` smallint(6) DEFAULT NULL, PRIMARY KEY (`id`) CLUSTERED ) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; DROP TABLE IF EXISTS `bookshop`.`book_authors`; CREATE TABLE `bookshop`.`book_authors` ( `book_id` bigint(20) NOT NULL, `author_id` bigint(20) NOT NULL, PRIMARY KEY (`book_id`,`author_id`) CLUSTERED ) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; DROP TABLE IF EXISTS `bookshop`.`ratings`; CREATE TABLE `bookshop`.`ratings` ( `book_id` bigint NOT NULL, `user_id` bigint NOT NULL, `score` tinyint NOT NULL, `rated_at` datetime NOT NULL DEFAULT NOW() ON UPDATE NOW(), PRIMARY KEY (`book_id`,`user_id`) CLUSTERED, UNIQUE KEY `uniq_book_user_idx` (`book_id`,`user_id`) ) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; ALTER TABLE `bookshop`.`ratings` SET TIFLASH REPLICA 1; DROP TABLE IF EXISTS `bookshop`.`users`; CREATE TABLE `bookshop`.`users` ( `id` bigint AUTO_RANDOM NOT NULL, `balance` decimal(15,2) DEFAULT '0.0', `nickname` varchar(100) UNIQUE NOT NULL, PRIMARY KEY (`id`) ) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; DROP TABLE IF EXISTS `bookshop`.`orders`; CREATE TABLE `bookshop`.`orders` ( `id` bigint(20) AUTO_RANDOM NOT NULL, `book_id` bigint(20) NOT NULL, `user_id` bigint(20) NOT NULL, `quality` tinyint(4) NOT NULL, `ordered_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) CLUSTERED, KEY `orders_book_id_idx` (`book_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin 后言 后言本专栏知识点是通过的系统学习,进行梳理总结写下文章,对c/c++linux系统提升感兴趣的读者,可以点击链接查看详细的服务:C/C++服务器开发。 |
 Server模块
Server模块 【本文地址】
今日新闻 |
推荐新闻 |